
We use cookies to understand how the website is being used and to ensure you get the best possible experience.
By continuing to use this site, you consent to this policy.
About cookies
THURSDAY, APR 19, 2018
We’re incredibly excited to announce our new geocoder, one of the most accurate and powerful geospatial tools on the market. To achieve this, we blended data from many sources and used artificial intelligence for natural-language processing. We also used millions of real-life examples to train our intelligent scoring system based on various parameters: textual match, composition, viewport, and even popularity. Read on to find out more.
Geocoding is the process of transforming a postal address or a name of a place into a location on the Earth's surface with exact longitude and latitude coordinates. Currently available geocoding solutions on the market weren’t precise enough or feature-rich to meet our standards. So we set out to create our own geocoding tool to match Google and outperform others like Esri, Mapzen, Maptitude, and OpenStreetMap. Check out the table below that compares Social Explorer’s accuracy with the industry’s most popular tools for the United States.
When we just started out building our geocoding solution, we used TIGER (short for Topologically Integrated Geographic Encoding and Referencing) and USPS open-source data as the foundation. However, we realized that in order to offer higher accuracy, we needed to go far beyond that, so in addition to the TIGER and USPS data, we also analyzed ways to incorporate OpenStreetMap, OpenAddresses, and Zillow data.
While all these data sources are publicly available, OpenStreetMap and OpenAddresses are crowdsourced and updated more frequently. TIGER and Zillow, on the other hand, are carefully managed by the Census Bureau and Zillow respectively, but are updated less frequently. However, all of these can be used together, e.g. OpenStreetMap for buildings, OpenAddresses for accurate house numbers, TIGER for roads and house number interpolations, Zillow for neighborhoods, etc.
Due to the various sources, the biggest challenge was preprocessing large amounts of data to create a unified database. This preprocessing was divided into multiple steps:
Download and transform original data
We downloaded large amounts of data from different sources, each of which uses a different format. For example, TIGER uses shapefiles, OpenStreetMap uses PBF, OpenAddresses and USPS use CSV files, etc. To make working with these heterogeneous data sources easier and faster, we converted all the gathered data into one single format. To facilitate this, we created a new file format for storing geometric and attribute data – with four times more compression power than the well-known-binary (WKB) and shapefiles.
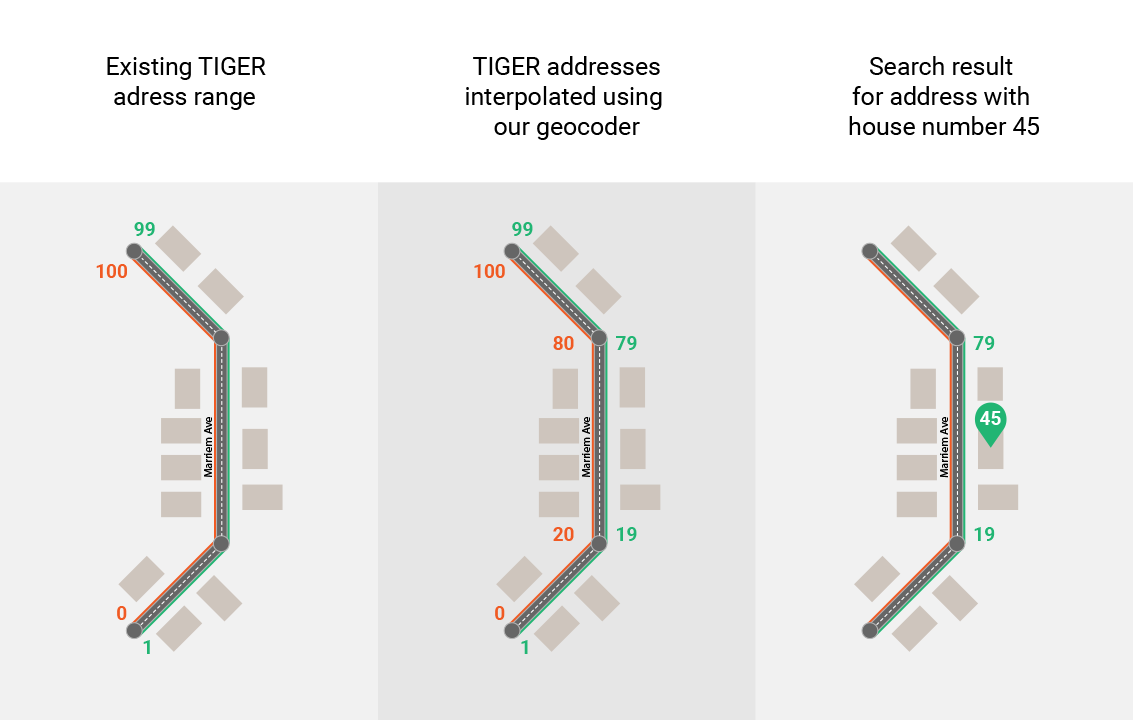
Additionally, TIGER house numbers are defined as ranges. This means that each road in TIGER has only the starting and ending house numbers. On the other hand, OpenAddresses provides exact locations of each house number. In order to combine these two data sources, we interpolated TIGER’s house numbers geometrically across roads to resemble OpenAddresses format. We used algorithms to extrapolate the missing street numbers based on the existing incomplete data.
Analyse and extract relevant data
Crowdsourced data sources such as OpenStreetMap are updated frequently, but the downside is that the data often contain duplicate and inaccurate entries. In this step, we extracted only the data relevant to the purpose of our geocoder and analyzed what each shape represents. For example, a polygon can represent both borders of a building or a ZIP code, so we used OpenStreetMap’s tag system to distinguish between different shapes and their representations.
Blending and deduplicating data
Combining data from multiple sources improves the overall accuracy. For example, OpenStreetMap has more accurate data when compared to OpenAddresses, which in turn has considerably more data on addresses.
Using multiple data sources, however, has its own drawbacks; namely, duplicate entries. Let’s take addresses in OpenAddresses as an example. While it covers a lot more addresses than other sources, there are many duplicate entries.

As you can see in the screenshot above, we compared the duplicate data entries (green and red dots) against OpenStreetMap’s data on buildings (blue polygons). Then, we used the dot closest to the center of the polygon to choose the best entry. While in some cases the difference is insignificant, there are cases where a duplicate dot is outside the bounds of the building they’re supposed to represent.
When all else fails and we can’t find the street numbers in OpenStreetMap or OpenAddresses, we use the interpolated TIGER addresses we mentioned earlier. For example, when you search for an address using our geocoder, first it searches for a matching address point. However, if the building you're looking for is new, the address you typed in is wrong or unofficial, or data hasn't been collected well for that area, we use the available addresses to interpolate where the missing address should be.
Another issue we ran into using multiple data sources was duplicate places. For example, Astoria, a neighborhood in Queens, is represented by a point in OpenStreetMap and a polygon in Zillow, and we sometimes have multiple, differently shaped polygons for the same place. In all of these cases, we evaluated these duplicates; prioritized and filtered them based on custom rules, e.g. TIGER places first, polygons over points, larger polygons over smaller polygons, etc.
Evaluate geographic hierarchy
In order to provide our users with the best result for each query, we had to evaluate the geographic hierarchy and relationship between all individual parts of that query. For example, if you search for “50 Merriam Avenue, Bronxville, NY”, we need to know the geographic relations of all the parts of that query. In other words, our geocoder needs to evaluate if “Merriam Avenue” is indeed in “Bronxville” and if “Bronxville” is indeed in “NY”. In this step, we preprocess these hierarchies for all geographies, such as roads, places, postal codes, counties, and states.
Artificial intelligence and natural-language processing
Reading and interpreting an address may seem as a simple task for humans, but for computers, it is a combinatorial challenge to evaluate all individual words or tokens within a query and determine which token represents a road, city, postal code, etc. We used artificial intelligence (AI) to train a natural-language processing (NLP) model that can accurately estimate these elements. Let’s take the “50 Merriam Avenue, Bronxville, NY” query as an example. Our NLP model is capable of estimating fairly accurately that “50” is a house number, “Merriam Avenue” road name, “Bronxville” a city and “NY” a state code. This model in most cases eliminates the need for a brute-force approach, which otherwise would be expensive for computers to evaluate.

On the surface, this may seem simple – a user simply enters the name of the city, for example, and Social Explorer finds it. However, beneath the surface, there are countless scenarios we need to take into consideration, which is why the algorithm behind Geocoder is one of the most powerful algorithms we ever worked on.
Let’s say you’re interested in “Washington”. There are 88 geographies in the United States with “Washington” in the name, whether they’re streets, parishes, cities, boroughs, or villages. Displaying the right one can be a challenge while searching through the entire database would be extremely taxing and take a lot of time and resources to complete. Throw in there a typo, and you’ll begin grasping the vast size of the challenge.
This is why we introduced intelligent scoring for returning the best search results and suggestions. This scoring is based on multiple parameters: textual match, composition, popularity, and viewport match.
One of the first parameters our geocoder takes into consideration is the textual match. Needless to say, exact matches are ranked first. However, as soon as you start typing, our geocoder starts offering suggestions and you can start expecting the right result after a few characters, long before you end typing the name of the area you’re looking for.
Even if you misspell a word, our geocoder implements fuzzy search using Levenshtein distance, a string metric to determine the term you wanted to type in. It calculates the number of characters that need to be deleted, replaced, or inserted to match an existing term. For example, searching for “Marriam Ave” is different from “Merriam Ave” by one character, and “Merriam Ave” should be suggested before “Maryam Ave”, which is different for two characters.
We score results based on the hierarchical relations of the individual parts of the query. For example, if a query contains a road followed by a city, and we determine that this road exists in that city, we rank that particular road higher compared to other roads with the same name but in different cities.
We collected billions of tweets with location metadata to figure out which locations are most popular and created a tweet heatmap. The reasoning behind this is that places with more tweets are more popular, and more likely to be the place people are searching for. For example, if users search for “Brooklyn”, the chances are that they are searching for “Brooklyn” in New York rather than “Brooklyn” in Portland, OR.

Another parameter our geocoder uses when you’re performing a search is the viewport, making it fully context-aware. As you type in the search term, geocoder not only searches matching areas but prioritizes them based on the map loaded on your screen. If you start typing in the name of a location that’s located both on the East and West Coast, but you’ve zoomed to the West Coast, results from the West Coast will be displayed before the results from the East Coast.
Considering the vast amount of data we ended up with on roads, zip codes and places, to name a few, it didn’t come as a surprise to us that the process of searching the entire database was a strenuous and lasting job. This is why, before releasing our latest tool to our users, we had to optimize it for faster performance, not only accuracy. For this task, we employed many techniques including dynamic programming.

Let’s take a look at the applications of dynamic programming through an actual example. Say a user enters 500 5th Ave, New York into our geocoder. Here, New York can represent both the city and the state of New York. This is why our geocoder searches through the entire database for combinations of all consecutive words:
"500 5th"
"500 5th Ave"
"500 5th Ave, NYC"
This means that for each search, our geocoder will have to run many searches and is more than likely to have multiple results for a single search. For example, 5th Avenue exists in many cities so our geocoder will return all 5th Avenues regardless of the city they’re in. Then, it will run another search for NYC which will return one result, which is New York. Then, it will compare all the results from the first search with the result in the second search.
500 5th Ave, NYC is a rather simple search term, but if you enter 500 5th Ave, Midtown, New York City, New York, you’re still referring to the same location, but the fact that you threw in there the house number, street, borough, city, and state, increased the number of results and comparisons between those results for a few millions.
Without dynamic programming, this query would run for a couple of seconds. However, since dynamic programming breaks each query down into a collection of simpler subproblems, solves each of those subproblems just once, and stores their solutions temporarily, the query will run up to ten times faster, lasting less than two hundred milliseconds.
Considering geocoding is a strenuous process and geocoding thousands of addresses simultaneously can get resource-intensive, we implemented our geocoder as a fully linearly scalable system in the cloud. The system detects cases of an increased number of geocoding requests and scales up the number of servers in the cloud and scales it down when the number of requests falls below a threshold. This, in addition to all the other optimizations we ran, ensures the service is always up and running and just as reliable, regardless of the number of requests being processed.
We already incorporated the latest version of our geocoder into Social Explorer, and you can take it for a spin in any of our maps right away. You may also use our geocoder on our new geospatial platform called GeoBuffer. Request access today.