





| Data Dictionary: | Community Resilience Estimates |
you are here:
choose a survey
survey details
Survey: Community Resilience Estimates
| Data Source: | Community Resilience Estimates; Social, Economic, and Housing Statistics Division; U.S. Census Bureau |
Survey Details
Community Resilience Estimates
Datasets
Documentation
Community resilience is the capacity of individuals and households within a community to absorb, endure, and recover from the impacts of a disaster. The Community Resilience Estimates are experimental estimates produced using information on individuals and households from the 2018 American Community Survey (ACS) and the Census Bureau’s Population Estimates Program as well as publicly available health condition rates from the National Health Interview Survey (NHIS).
The ACS is a nationally representative survey with data on the characteristics of the U.S. population. The sample is selected from all counties and county-equivalents in the U.S. and has a sample size of about 3.5 million addresses for the 2018 year survey. Publicly available data from the 2018 National Health Interview Survey (NHIS) are incorporated. The NHIS is the principal source of information on the health of the non-institutionalized population of the U.S. The NHIS is a cross-sectional household interview survey with about 35,000 households containing about 87,500 persons. Auxiliary data are used from the Population Estimates Program by tract, age group, race and ethnicity, and sex.
Modeling techniques used to develop the estimates are flexible and can be modified for a broad range of disasters (hurricanes, tornadoes, floods, etc.). These experimental estimates, in their current form, are specific to the current pandemic but could be modified to fit other disease outbreaks or weather-related disasters with differing risk factors. Local planners, policy makers, public health officials, and community stakeholders can use the estimates as one tool to help assess the potential resiliency of communities and plan mitigation strategies.
Resilience to a disaster is partly determined by the vulnerabilities within a community. In order to measure these vulnerabilities, we designed an individual risk index. Within this risk index, binary risk components are defined, adding up to 11 possible risks. A risk index is constructed using the weighted aggregate of risk factor. The specific measures we use are below.
ACS-defined Risk Factors (RF) for Households (HH) and Individuals (I)
Weighted area-level tabulations of tallies and rates for each group are calculated, and accompanying direct replicate weight-based sampling variances are processed. Direct estimates and accompanying standard errors are produced and fed directly into a synthetic auxiliary proxy index. This index is used to assign indirect shares estimates, producing aggregate-level standard error calculations and subsequent shrinkage small area estimates.
The ACS-defined components are constructed and modeled jointly. Then, domain-defined variables are appended as a function of domain affiliation. Probabilities for the health risk components are derived from published NHIS tables by region, age group, sex, race, and Hispanic origin. Correlation among components are only to the level of their aggregation.
For each individual a set k of possible risk factors are defined. Each risk factor is binary, so let δik∈{1,0} be the outcome for risk factor k and individual i, with probability,Pik. The outcomes are dependent. For example, consider the two risk factors of low income and unemployed. The probability of being low income is much higher if one is unemployed (and vice versa). At the micro level, we have a set of dependent Bernoulli-distributed variables at the micro-level.
We use micro level data to produce a measure at the domain level. This measure is the number of people facing a specific number of risk factors. For each domain, we produce k such measures. Conceptually, at the person level, the measure is a sum of risk factors. For individual risk factor tallies of d = 0..k risk factors:
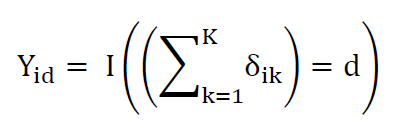
Where = I(.) represents the indicator function, equals one if condition is true, zero otherwise. So for each individual, the outcome Y is vector of length k. Each element is a 1 or 0 representing whether that individual has that number of risk factors. These indicators represent a realization from a series of dependent Bernoulli distributions. This is generally termed a multivariate Bernoulli distribution.
Modeling techniques used to develop the estimates are flexible and can be modified for a broad range of disasters (hurricanes, tornadoes, floods, etc.). These experimental estimates, in their current form, are specific to the current pandemic but could be modified to fit other disease outbreaks or weather-related disasters with differing risk factors. Local planners, policy makers, public health officials, and community stakeholders can use the estimates as one tool to help assess the potential resiliency of communities and plan mitigation strategies.
Resilience to a disaster is partly determined by the vulnerabilities within a community. In order to measure these vulnerabilities, we designed an individual risk index. Within this risk index, binary risk components are defined, adding up to 11 possible risks. A risk index is constructed using the weighted aggregate of risk factor. The specific measures we use are below.
ACS-defined Risk Factors (RF) for Households (HH) and Individuals (I)
- RF 1: Income-to-Poverty Ratio (IPR) < 130 (HH).
- RF 2: Single or zero caregiver household –only one or no individuals living in thehousehold who are 18-64 (HH).
- RF 3a: Unit-level crowding - persons per room over 0.75 (HH)
- RF 4: Communications barrier –linguistically isolated or no one in the household with ahigh school diploma (HH)
- RF 5: No employed persons (HH)
- RF 7: Disability posing constraint to significant life activity (I)
- RF 8: No health insurance coverage (I)
- RF 6: Age >= 65 (I)
- RF 3: RF 3a = 1 or more persons reside within high-density tract (HH)
- RF 9: Serious heart condition (I)
- RF 10: Diabetes (I)
- RF 11: Emphysema or current asthma (I)/li>
Weighted area-level tabulations of tallies and rates for each group are calculated, and accompanying direct replicate weight-based sampling variances are processed. Direct estimates and accompanying standard errors are produced and fed directly into a synthetic auxiliary proxy index. This index is used to assign indirect shares estimates, producing aggregate-level standard error calculations and subsequent shrinkage small area estimates.
The ACS-defined components are constructed and modeled jointly. Then, domain-defined variables are appended as a function of domain affiliation. Probabilities for the health risk components are derived from published NHIS tables by region, age group, sex, race, and Hispanic origin. Correlation among components are only to the level of their aggregation.
For each individual a set k of possible risk factors are defined. Each risk factor is binary, so let δik∈{1,0} be the outcome for risk factor k and individual i, with probability,Pik. The outcomes are dependent. For example, consider the two risk factors of low income and unemployed. The probability of being low income is much higher if one is unemployed (and vice versa). At the micro level, we have a set of dependent Bernoulli-distributed variables at the micro-level.
We use micro level data to produce a measure at the domain level. This measure is the number of people facing a specific number of risk factors. For each domain, we produce k such measures. Conceptually, at the person level, the measure is a sum of risk factors. For individual risk factor tallies of d = 0..k risk factors:
Where = I(.) represents the indicator function, equals one if condition is true, zero otherwise. So for each individual, the outcome Y is vector of length k. Each element is a 1 or 0 representing whether that individual has that number of risk factors. These indicators represent a realization from a series of dependent Bernoulli distributions. This is generally termed a multivariate Bernoulli distribution.


Community Resilience Estimates; Social, Economic, and Housing Statistics Division; U.S. Census Bureau

